Website Knowledge Source
Extracting content from websites can be challenging, as it requires isolating the main content from extraneous elements. EpisBase utilizes advanced AI techniques to effectively perform this extraction through a process known as crawling.
Responsible Crawling Practices
Web crawling involves systematically browsing the web to index and retrieve content. It’s crucial to conduct crawling responsibly to avoid overloading websites and to respect their data policies. Key considerations include:
-
Respecting
robots.txtFiles: Websites userobots.txtfiles to communicate which parts of the site should not be crawled. EpisBase adheres to these directives to ensure compliance with site owners’ preferences. -
Avoiding Excessive Requests: High-frequency crawling can strain website servers, leading to increased operational costs and potential service disruptions. EpisBase implements rate limiting to prevent such issues.
-
Ethical Data Usage: Some websites may not wish their data to be used by third parties. EpisBase respects such preferences, aligning with ethical standards in data usage.
Adding a Website Knowledge Source
To add a website as a knowledge source in EpisBase:
-
Initiate Website Extraction:
- In the “Add Knowledge Source” dialog, select the “Website” option.
- Enter the root URL of the website (e.g.,
https://example.com). Avoid specifying subdirectories (e.g.,/blog) to ensure comprehensive extraction.
-
Test Website Compatibility:
- Click “Check Website” to allow EpisBase’s AI to assess the site’s structure and extractable content.
- This process may take a few moments. Upon completion, a preview of extractable links will be displayed, indicating the feasibility of extraction.
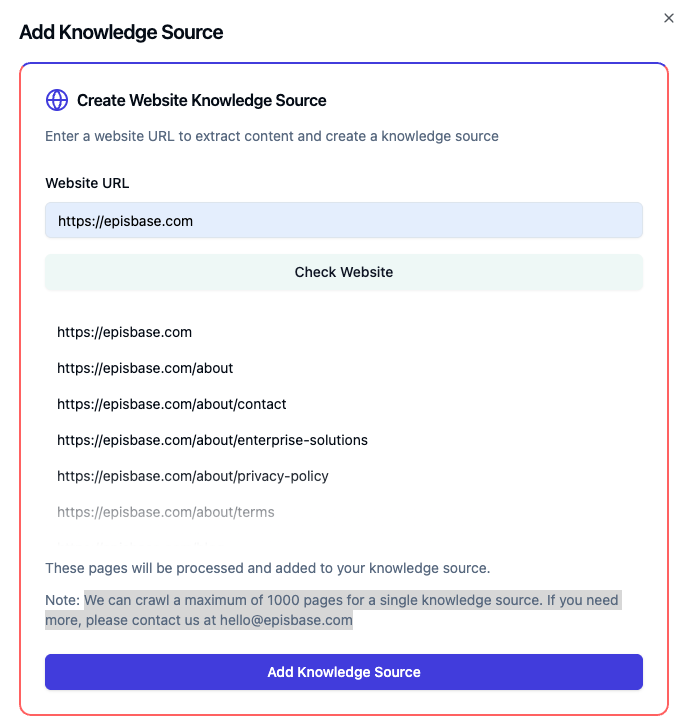
Note: EpisBase can crawl up to 1,000 pages per knowledge source. For requirements exceeding this limit, please contact us at hello@episbase.com.
-
Confirm and Initiate Crawling:
- After reviewing the preview, click “Add Knowledge Source” to commence the crawling process.
- The duration of this process varies based on the site’s size and complexity.
-
Access and Utilize Extracted Content:
- Once processing is complete, the extracted content will be available for use within EpisBase’s features, such as chat applications and quizzes.
The extraction and processing services are free of charge.